Spider Bot for Discord
Spider Bot lets you crawl, scrape, and screenshot websites directly from Discord using slash commands. Add it to your server and start pulling web data without leaving the chat.
Install the Bot
Add Spider Bot to your server. Select a server and grant the requested permissions.
Authenticate
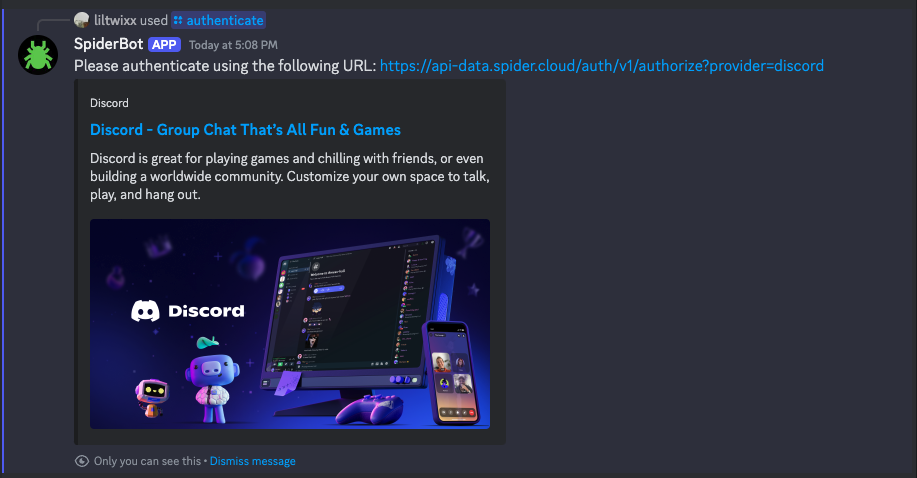
Before crawling, link your Spider account:
/authenticateFollow the prompts to enter your Spider credentials. You also need credits to make requests. Purchase credits on the web, or reload from Discord:
/purchase_creditsCrawl a Website
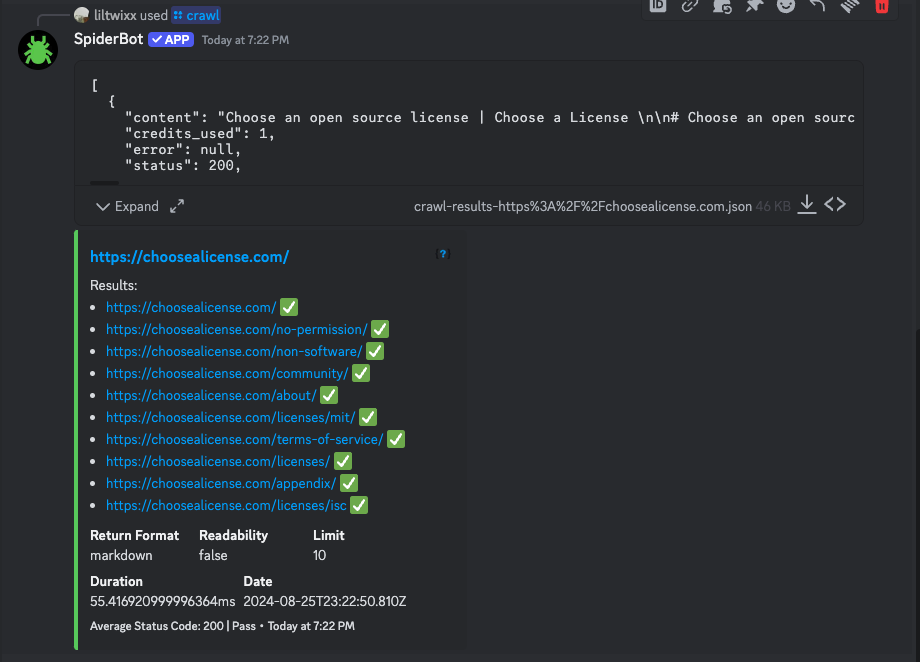
/crawl url:<website_url> limit:<number_of_pages> return_format:<format> readability:<true_or_false>- url: The website to crawl
- limit: Number of pages (up to 40)
- return_format:
raw,markdown,commonmark, orbytes - readability: Clean content for LLM consumption
Scrape a Single Page
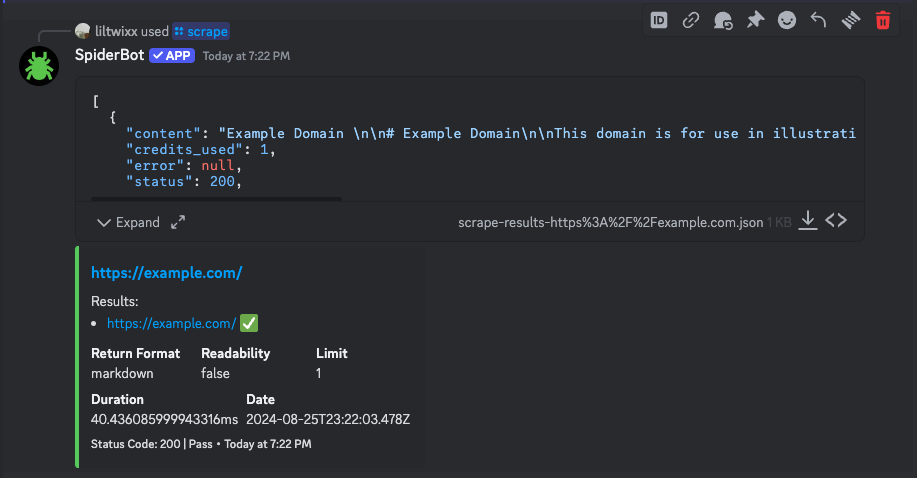
/scrape url:<website_url> return_format:<format> readability:<true_or_false>Same parameters as crawl, but fetches a single page instead of following links.
Take a Screenshot
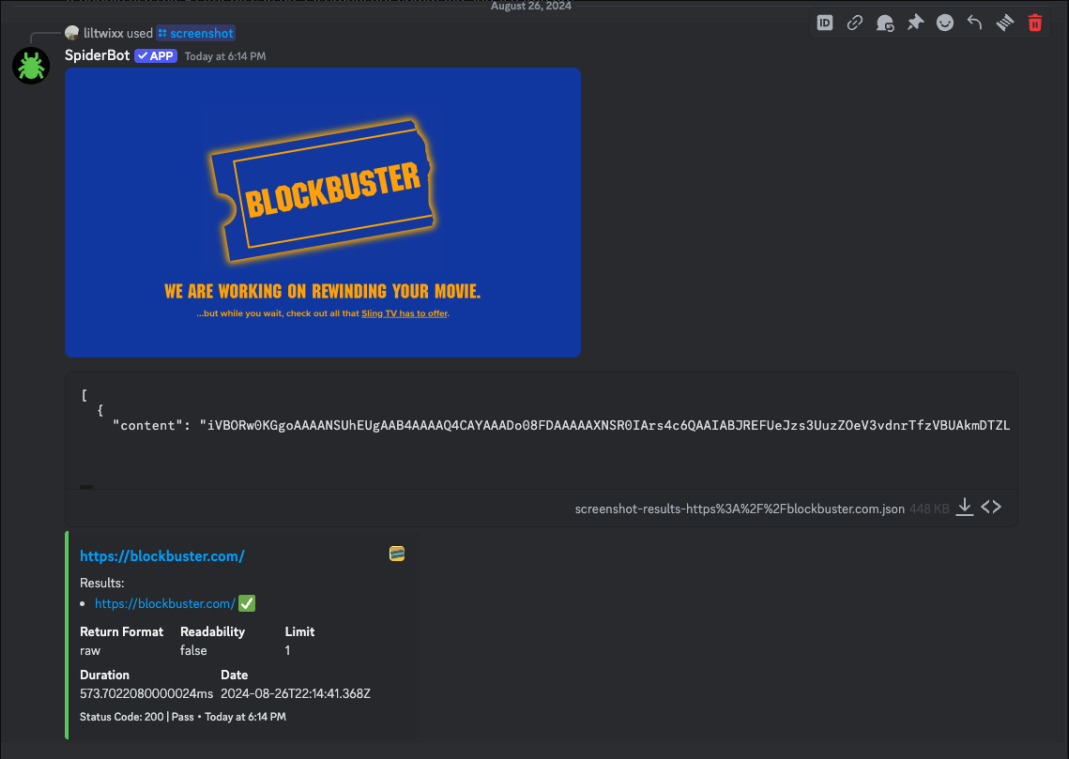
/screenshot url:<website_url>Captures a full-page screenshot and posts it in the channel.
Pair with AI Bots
Once you have web data in the channel, AI bots can work with it directly.

Query extracted content, generate images from data, or convert text to video. Spider outputs LLM-ready formats, so AI tools can process the results without additional formatting.
Add Spider Bot to your server to get started.
Start crawling in 30 seconds.
One API key. No servers to manage.
Free balance on signup · No card required