Extract Leads from Websites
Spider can extract contact information (emails, phone numbers, names, titles) from any website using AI. The crawler handles page access and anti-bot measures, while AI models pull structured contact data from the page content regardless of HTML layout.
Extract from the Dashboard
The fastest way to extract contacts is through the Spider dashboard:
- Crawl the target website from your dashboard.
- Open the page you want to extract contacts from.
- Click the dropdown menu and select Extract Contact.
- Wait 10-60 seconds for AI processing.
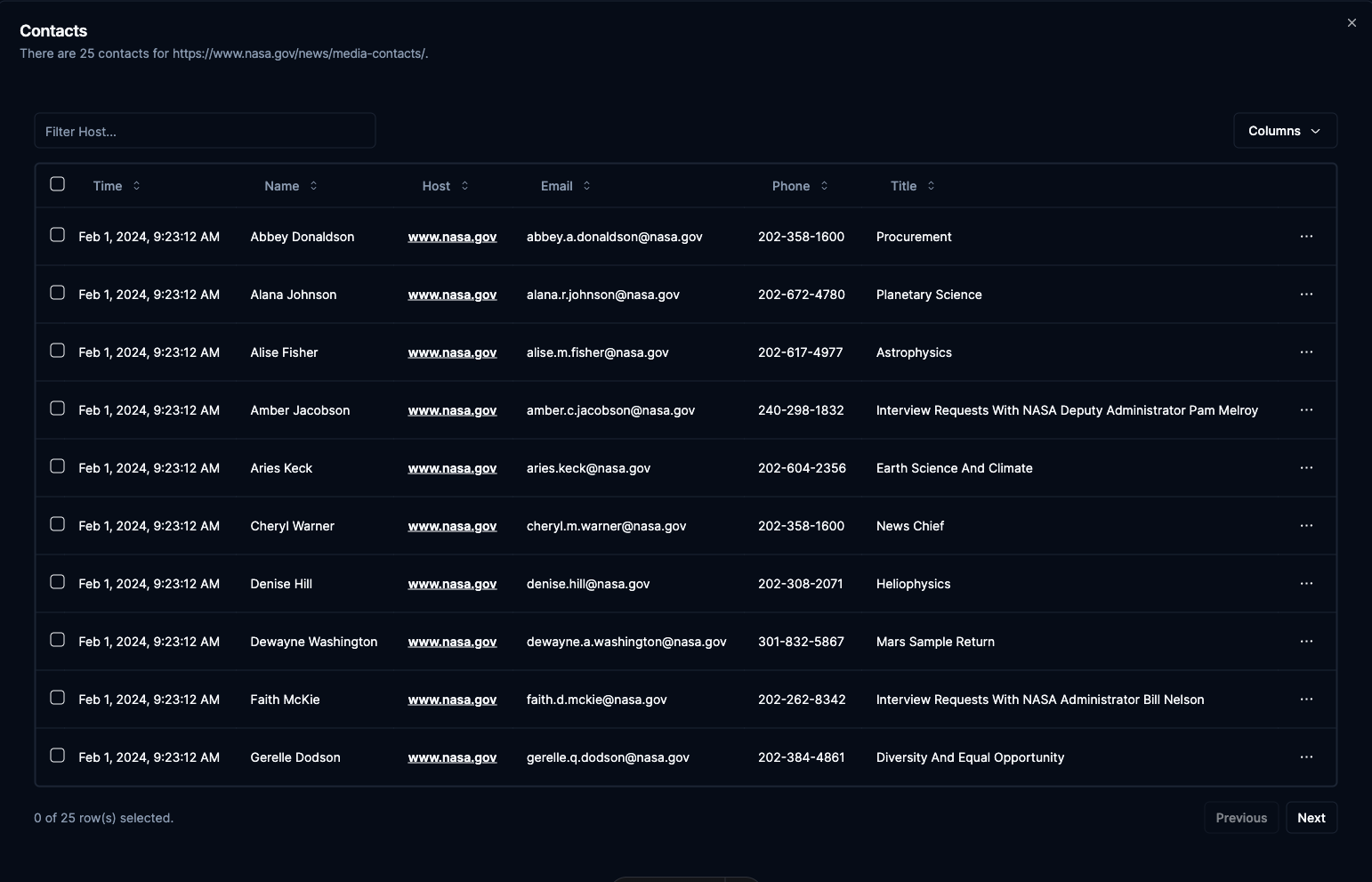
Results appear in a grid showing name, email, phone, title, and source website.
Extract via API
Use the /pipeline/extract-contacts endpoint to extract contacts programmatically. All parameters are optional except url. Use prompt to customize how the AI handles extraction. Set store_data to save extracted contacts with the page in your dashboard.
import requests, os, json
headers = {
'Authorization': f'Bearer {os.getenv("SPIDER_API_KEY")}',
'Content-Type': 'application/json',
}
response = requests.post('https://api.spider.cloud/v1/pipeline/extract-contacts',
headers=headers,
json={
"url": "https://example.com/team",
"limit": 1,
"model": "gpt-4o",
"prompt": "Extract all team member contact information"
},
stream=True
)
for line in response.iter_lines():
if line:
print(json.loads(line))Reduce Costs with Link Filtering
For large sites, you can save credits by filtering links before running extraction. Use the /links endpoint to gather all URLs, then /pipeline/filter-links to narrow down to pages likely to contain contacts (like /team, /about, /contact pages), and finally run /pipeline/extract-contacts only on the filtered set.
Loading graph...
This pipeline approach can cut extraction costs significantly on sites with hundreds of pages where only a few contain contact information.
Note: The
/pipeline/filter-linksendpoint is deprecated. Use CSS selectors or crawl parameters to filter URLs instead.
Start crawling in 30 seconds.
One API key. No servers to manage.
Free balance on signup · No card required